

Johan Porsby
En bra datamodell är av stor betydelse för att ett data warehouse ska ge den nytta man önskar. Jag kommer här gå igenom olika modeller och deras för- och nackdelar. Ofta kan olika datamodeller passa bäst i olika delar av ett data warehouse.
Stjärnan
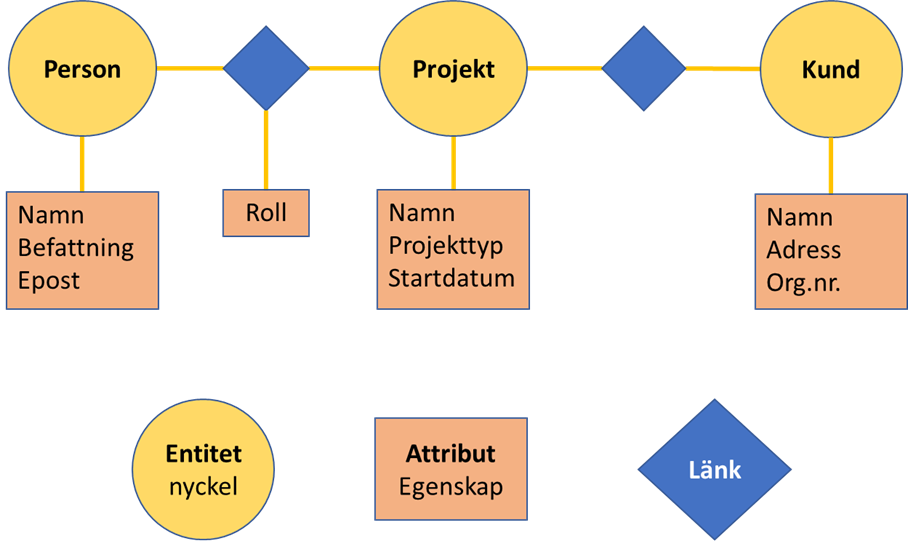
Den kanske vanligaste datamodellen i ett data warehouse är en dimensionsmodell, även kallad stjärna eller kub. En enkel stjärna är rent logiskt en flat tabell, men man brukar skilja på fakta och dimensionsdata i olika tabeller för att spara lagring och öka prestanda, men för mindre datamängder fungerar en flatfil utmärkt. Fördelen med en stjärna är att många frågor blir enkla att formulera och ger snabba svar. Det gäller särskilt så kallade ”slice and dice”-frågor som ”försäljning av elcyklar per månad i Stockholm under 2020”. Många grafiska analysverktyg som Power BI, Qlik med flera, fungerar också bäst med en dimensionsmodell i botten. Men en effektiv dimensionsmodell kräver att man vet ungefär vilka frågor som kommer ställas, så att modellen innehåller de mätvärden som efterfrågas och de attribut man vill använda för att filtrera och gruppera sitt data på. Vet man inte det kan en normaliserad datamodell vara mer flexibel, men analysen kräver då mer av användaren, ofta behöver man kunna SQL.
Dimensionsmodell
Grundlager och analyslager
I större datalager skiljer man ofta på grundlagret och ett eller flera analyslager, så kallade data marts. Grundlagret är där man lagrar allt data man samlat på sig. Ofta används en mer eller mindre normerade datamodell i grundlagret. Grundidén med en normaliserad datamodell är att data inte ska dupliceras. Detta är effektivt för uppdateringar, men inte alltid för frågor, då man kan behöva läsa från många tabeller.
I analyslagren är informationen anpassad för olika analyser. Säljavdelningen kanske har ett analyslager och controllers ett annat. Analyslagren har ofta en dimensionsmodell.
Idag finns en trend att i grundlagret spara data i sitt ursprungliga råa format, som det kommer från källsystemet. Fördelen är dels att det inte behövs någon ny modellering, dels att man inte förvanskar eller tappar någon information vid transformering. Nackdelen är att informationen kan bli svårt att tolka. En annan utmaning är om källsystemen har en hög förändringstakt, så kan det bli besvärligt att hela tiden ändra datamodellen. En filbaserad ”Data Lake” kan då fungera bättre för lagring över tid. Men problemet att tolka data kvarstår.
Enterprise Data Model
Ett sätt att förenkla tolkningen av data är att bygga en gemensam datamodell för ”allt”, en Enterprise Data Model (EDM). Detta har dock visat sig vara svårt och idag avråder många från detta. Men ibland kan det vara relevant, särskilt om man har många källsystem som innehåller data av liknande typ, till exempel i en koncern där dotterbolagen har olika ekonomisystem, men där mycket ekonomisk rapporteringen sker centralt. Då kan det vara praktiskt med en gemensam datamodell för den ekonomiska informationen. Modelleringen behöver inte bli alltför komplicerad då mycket ekonomisk rapportering ofta är tämligen väldefinierad.
Ett annat exempel är inom bank, där det kan finnas många system och produkter som hanterar olika typer av lån (bostadslån, företagslån, kortkrediter, leasingavtal med mera) som man behöver kunna hantera gemensamt för beräkning av riskexponering och kapitaltäckningsbehov samt rapportering till myndigheter. Då kan det vara lönt att samla informationen i en gemensam datamodell, även om det är svårt och resurskrävande.
Men har man bara ett system för CRM, ett för projektuppföljning respektive ett ekonomisystem är det tveksamt om man bör försöka trycka in allt detta i en gemensam datamodell. Det kan dock vara klokt att dela masterdata, såsom kunder, produkter och den egna organisationen, för att enkelt kunna analysera data från flera källor tillsammans.
Flexibilitet
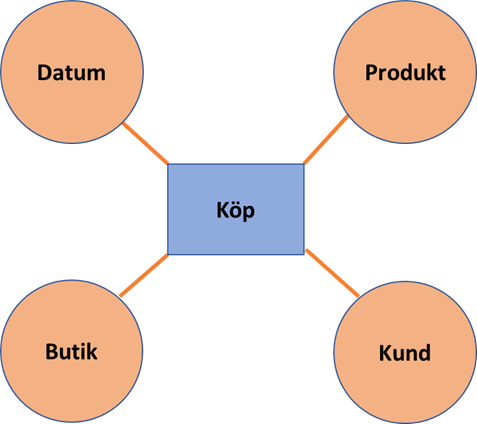
En datamodell för ett grundlager måste vara flexibel för att möta nya krav. Ett data warehouse lever ofta länge och måste kunna hantera nya och förändrade datakällor. Modeller som hanterar förändringar bra är entitetbaserade modeller, till exempel Data Vault eller ankarmodeller. Dessa har huvudsakligen tre typer av tabeller: entiteter som motsvarar affärsobjekt, relationer mellan objekt och egenskaper på objekt och relationer. En entitet kan till exempel vara en kund, produkt eller ett köp. Entiteten innehåller bara objektets nyckel. Alla egenskaper hålls i separata tabeller. Dessa kan vara historiserade med angivna tidpunkter för när ett värde är giltigt. Den tredje typen av tabell är relationer mellan entiteter. Även dessa kan vara historiserade. Nya relationer kan därför enkelt hanteras då främmande nycklar har ersatts med relationstabeller. Sambanden mellan objekt kan lätt ändras över tid. I normala fall kanske man har en direkt relation till kunden, men i andra fall går den via en mellanhand. Båda varianterna kan lätt realiseras då relationstabellerna styr hur objekten hänger ihop.
Entitetsbaserad datamodell
En entitetsbaserad modell kan fungera väl i ett grundlager, men sämre i analyslager eftersom de är svårare att tolka.
Ju mer generell modellen görs, desto mer flexibel blir den. Kund kan kanske slås ihop med säljare/handläggare och organisationsenhet till ett gemensamt objekt ”part”. Olika egenskaper som en produkts färg och vikt kan lagras i separata fält, men de kan också lagras i samma fält, med en egenskapstyp som kvalificerar. Behöver man lägga till en ny egenskap längd, krävs ingen ny kolumn utan bara en ny egenskapstyp ”Längd”. Modellen blir mer flexibel, men också mer svåröverskådlig. Ibland kombineras båda sätten, vanliga egenskaper får egna fält, medan andra lagras i en separat tabell för godtyckliga egenskaper. Generella fält kan vara användbart i en produktdatabas där olika produkter har olika relevanta egenskaper: antal växlar för en cykel, skärmstorlek för en mobiltelefon.
Andra aspekter
Vissa analyser kräver kanske inte bara en speciell datamodell, utan en speciell typ av databas, till exempel en grafdatabas eller en databas för geodata (GIS).
Idag är prestanda och lagringsvolymer ett mindre problem, men ibland kan man behöva ta hänsyn till detta vid modelleringen. En annan avvägning är om man ska välja den optimala lösningen för uppgiften eller om man ska välja en beprövad teknik som många är bekanta med. Det finns inget givet svar på vilken datamodell som är bäst, men det är aldrig fel att fundera över frågan. Enkelhet har också sina fördelar. Är ett kalkylark tillräckligt bra för att lösa uppgiften, krångla inte till det mer.
Vill du veta mer om Agero? Lämna dina kontaktuppgifter så hör vi av oss!
Dela den här bloggen


Senaste från bloggen
Prenumerera på bloggen
Fler bloggar från oss



Kontakta oss
Nyfiken på oss? Hör av dig så tar vi ett snack – oavsett om det gäller IT-stöd eller nästa steg i karriären.
